


Research Goals & Aims
The primary goal of this research is to understand the lifespan changes of the vocal tract anatomy in both typically and atypically developing populations, and also to examine the relation of anatomic changes to speech acoustics. We accomplish this using a combination of three approaches: Imaging, acoustics, and vocal tract (VT) modeling.
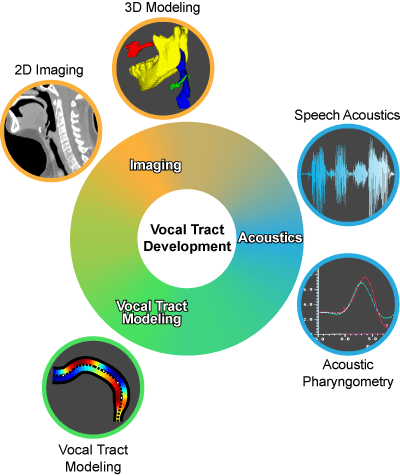
Imaging
We have established a unique imaging database with more than 1900 imaging studies (MRI and CT), across the lifespan, for both typically developing individuals of both sexes and atypically developing individuals (Down syndrome, cerebral palsy, etc.). Using this database, we have compiled a set of landmark-based measurements, and we have been systematically characterizing how the VT structures grow individually and in relation to one another. Additionally, we are currently rendering 3D models of select VT structures and advancing novel analysis methods to quantify multidimensional growth, taking into account tissue type, embryologic origin and function.
Acoustics
Efforts are underway to establish a speech acoustics database between the ages 2 to 90 years. Our current database consists of over 230 recordings from typically developing participants and over 150 recordings from participants with Down syndrome. We work to compile a database of acoustic measurements from these recordings, some of which are unprecedented in design. Recordings are also supplemented by use of an acoustic pharyngometer, where participants breathe into its tube and the reflection of sound waves are used to measure VT dimensions. This combination of acoustic and VT dimension measures will help enable more rigorous testing of anatomic-acoustic relations. Furthermore, we are examining accuracy of measurements of various acoustic analysis software packages, and exploring new approaches for acoustic analysis as well as the quantification and visualization of vowel formant development.
VT Modeling
Current efforts entail testing hypotheses on anatomic-acoustic relations using the acoustic output of the sex-specific developmental VT models that we have advanced.